Python爬虫搜索并下载图片
本文是我学习Python爬虫的笔记,一直想要再学一门语言来扩展自己的知识面,看了看各种语言主要使用的方向,最后决心还是来搞一搞 Python.Python 给我的第一印象就是语法简洁,格式另类还有各种库的支持,就喜欢这么有个性的语言,为了以后深入的学习爬虫,事先肯定是先把语法学了一遍,下面是我实现的一个小爬虫,可以通过百度图库利用关键字来搜索图片并下载
工具准备:
- 不要多想,挑个IDE吧,我用的是PyCharm(免费的~嗯,今年刚刚免费的)
- 打开PyCharm的设置(找找在哪,我都是直接commond+,的,如果你有commond键的话)在Project下选择Project Interpreter然后点击左下角的加号,在输入框中输入requests,收索后安装,其实还有很多其他的安装方法,使用pip,在终端中敲入那些代码,然后还有什么其他的东西,不过还是这样比较偷懒(其实前面的坑我都爬过了)
- Python为最新版,2.7应该也没问题,并未使用Scrapy爬虫框架,也没有使用lxml,仅仅使用re正则和requests网络请求
re和requests用法
- re正则
re就是正则,主要是用来解析数据的,当我们拿到网页的数据时需要从中提取处我们想要的数据,正则匹配就时其中的一个方法,至于正则的写法,这里就不在多讲,想看的在这里正则表达式30分钟入门教程,而re的常用使用手法可以在我的这篇文章里了解Python爬虫-re(正则表达式)模块常用方法,这里我们主要使用其re.findall("正则表达式","被匹配数据",匹配限制(例如:忽略大小写)) - requests网络请求
requests的封装异常的强大,几乎可以做任何形式的网络请求,这里我们只是使用了其最简单的get请求requests.get("url",timeout=5),详细了解,可以看一下(requests快速入门)
具体的步骤
- 首先是想清楚想要做什么,你想要获取什么数据(没有目标哪来的动力啊),这里我们是想要通过百度图片来后去图片链接及内容,我想要搜索关键字,并可以指定搜索的数据量,选择是否保存及保存的路径~
- 需求有了,就要去分析要爬去的网页结构了,看一下我们的数据都在哪,我们这次要扒去的图片来自百度图片
- 首先进入百度图库,你所看见的页面当向下滑动的时候可以不停的刷新,这是一个动态的网页,而我们可以选择更简单的方法,就是点击网页上方的传统翻页版本
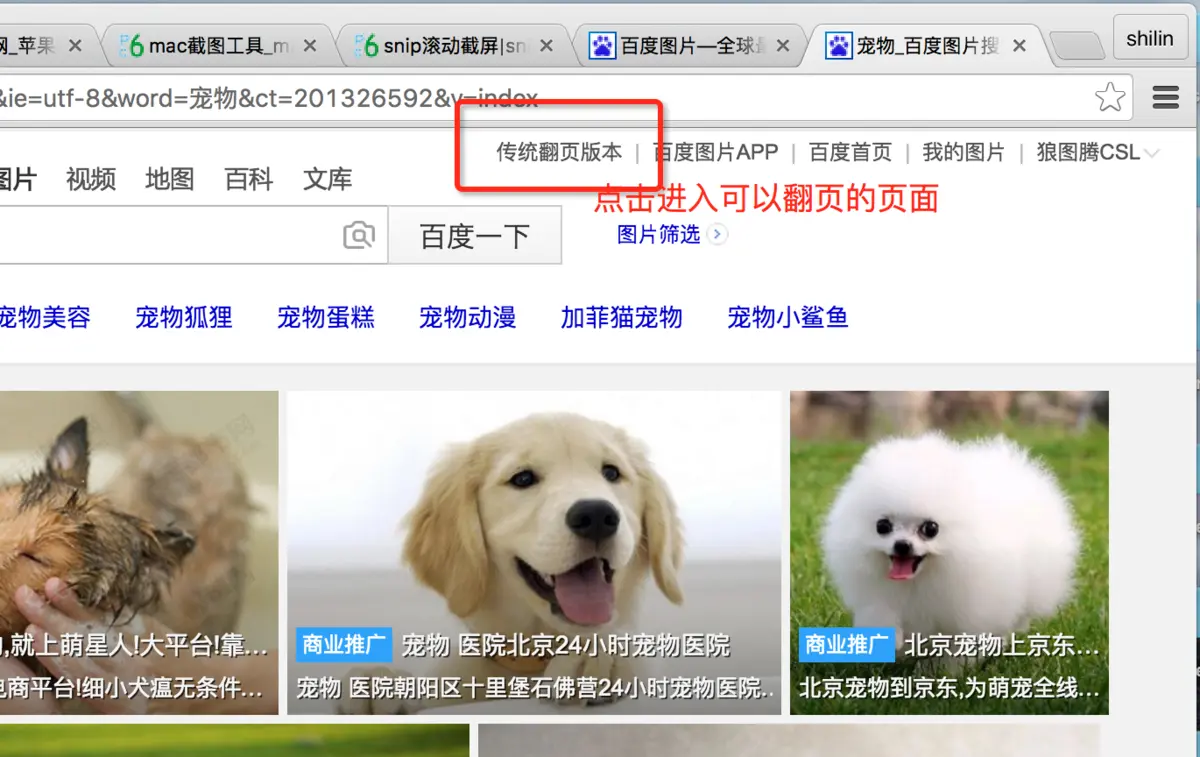
- 接下来就是我们熟悉的翻页界面,你可以点击第几页来获取更多的图片
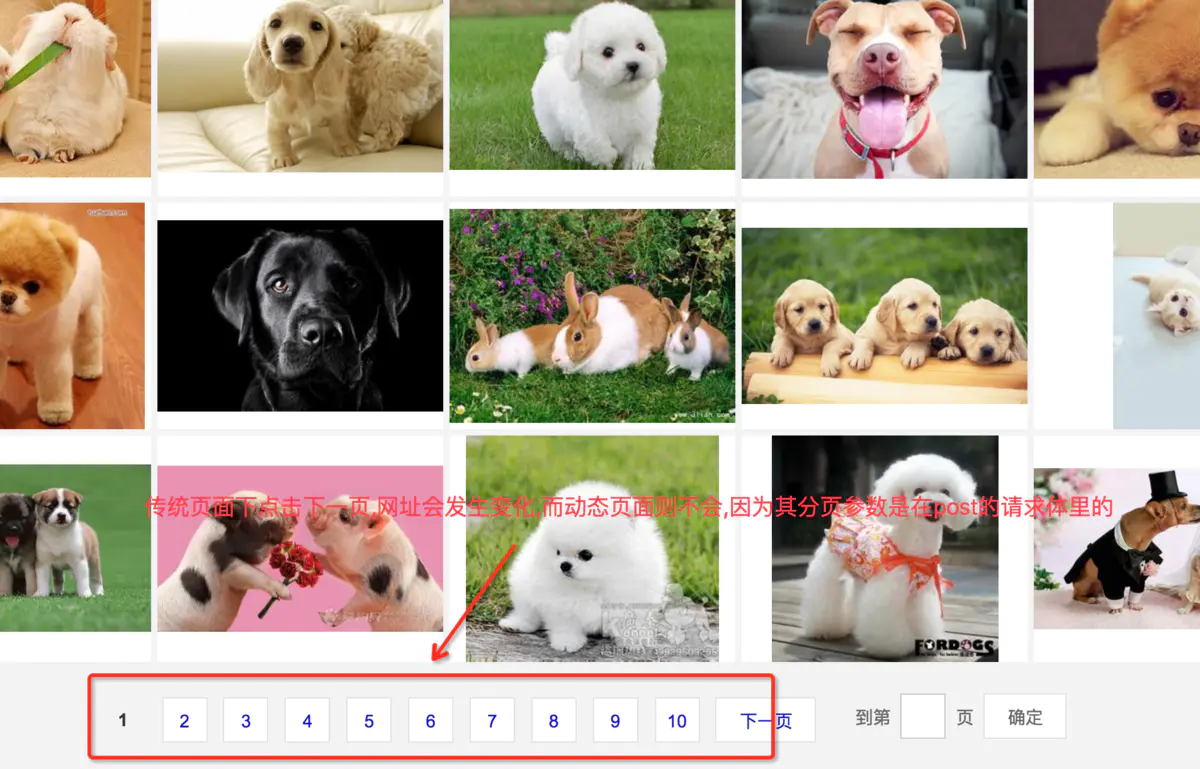
- 点击鼠标的右键可以查看网页的源代码,大概就是这个样子的,我们get下来的数据,就是这个啦,我们需要在这里面找到各个图片的链接和下一页的链接,然而有点懵,这么多的数据,我们想要的在哪里呢?
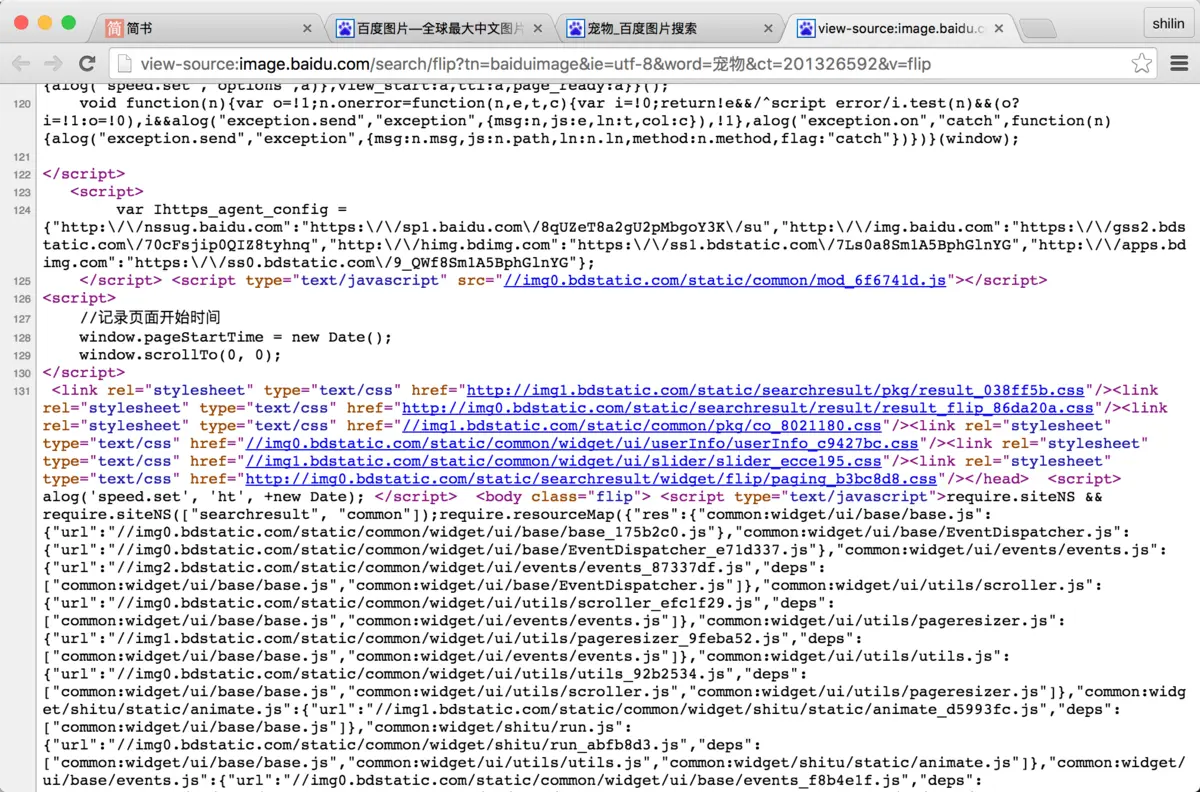
- 不着急,我们可以通过浏览器的开发者工具来查看网页的元素,我用的是 Chrome,打开 Developer Tools 来查看网页样式,当你的鼠标从结构表中划过时会实时显示此段代码所对应的位置区域,我们可以通过此方法,快速的找到图片所对应的位置:
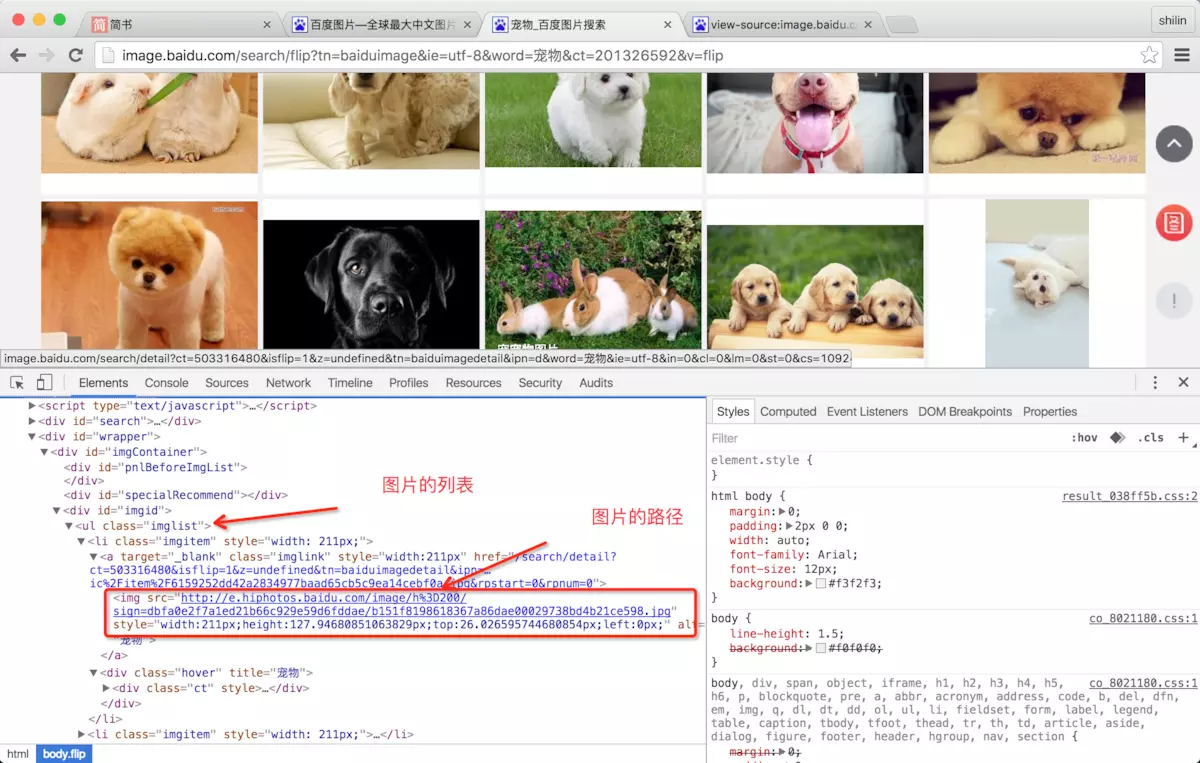
找到了一张图片的路径和下一页的路径,我们可以在源码中搜索结果找到他们的位置,并分析如何书写正则来获取信息:
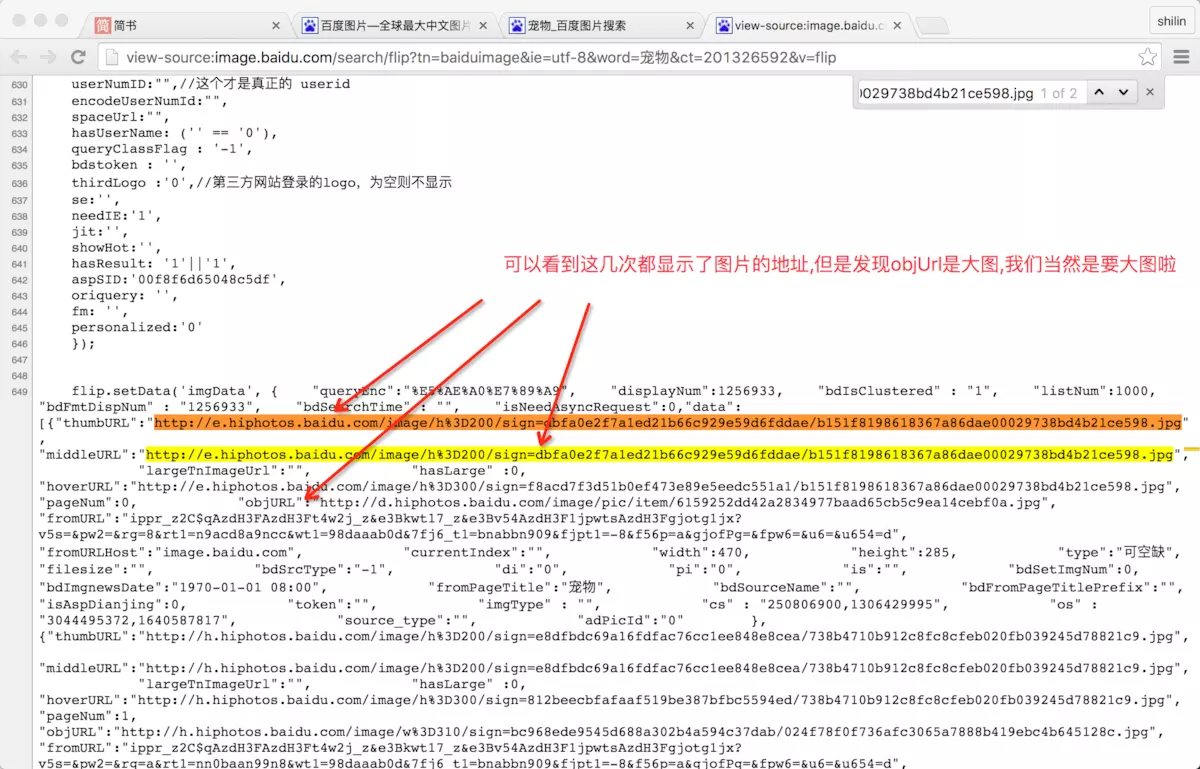
- 所有的数据都分析完毕了,这个时候就要开始写我们的爬虫了,看了这么久,竟然一句代码都没有:
1 | import requests #首先导入库 |
然后设置默认配置
1 | MaxSearchPage = 20 # 收索页数 |
图片链接正则和下一页的链接正则
1 | def imageFiler(content): # 通过正则获取当前页面的图片地址数组 |
爬虫主体
1 | def spidler(source): |
爬虫的开启方法
1 | def beginSearch(page=1,save=0,savePath="/users/caishilin/Desktop/pictures/"): # (page:爬取页数,save:是否储存,savePath:默认储存路径) |
调用开启的方法就可以通过关键词搜索图片了
1 | beginSearch(page=1,save=0) |
小结
因为对 Python 的理解还不是特别的深入,所以代码比较繁琐,相比较爬虫框架 Scrapy 来说,直接使用 reqests 和 re 显得并不是特别的酷,但是这是学习理解爬虫最好的方式,接下来我会陆陆续续将我学习爬虫框架 Scrapy 的过程写下来,有错误的地方请指正。
